淺談大數據的過去、現在和未來
時間:2022-06-14來源:互聯網瀏覽數:592次
相信身處于大數據領域的讀者多少都能感受到,大數據技術的應用場景正在發生影響深遠的變化: 隨著實時計算、Kubernetes 的崛起和 HTAP、流批一體的大趨勢,之前相對獨立的大數據技術正逐漸和傳統的在線業務融合。關于該話題,筆者早已如鯁在喉,但因拖延癥又犯遲遲沒有動筆,最終借最近參加多項會議收獲不少感悟的契機才能克服懶惰寫下這片文章。
本文旨在簡單回顧大數據的歷史,然后概括當前的主要發展趨勢以及筆者的思考,最后不免主觀地展望未來。
01、過去:先進與落后并存
大數據起源于 21 世紀初 Web 2.0[1] 帶來的互聯網爆發性增長,當時 Google、雅虎等頭部公司的數據量級已經遠超單機可處理,并且其中大部分數據是網頁文本這樣的非結構化、半結構化數據,用傳統的數據庫基本無法處理,因此開始探索新型的數據存儲和計算技術。在 2003-2006 年里,Google 發布了內部研發成果的論文,即被稱為 Google 三駕馬車的 GFS、MapReduce 和 Bigtable 論文。在此期間,雅虎基于 GFS/MapReduce 論文建立了開源的 Hadoop 項目,奠定了后續十多年大數據發展的基礎,也在同時大數據一詞被廣泛被用于描述這類數據量過大或過于復雜而無法通過傳統單機技術處理的系統[2]。
然而,雖然以 MapReduce 作為代表的通用數據存儲計算框架在搜索引擎場景獲得巨大成功,但是在于之存在競爭關系的數據庫社區看來,MapReduce 是一次巨大的倒退(”A major step backwards”)[3]。主要原因大致如下:
編程模型的巨大倒退,缺乏 schema 和高級數據訪問語言
實現非常原始,基本是暴力遍歷而不是使用索引
理念落后,是 25 年前的技術實現
缺少當時 DBMS 標配的大部分特性,比如事務、數據更新
與當時 DBMS 用戶依賴的工具不兼容
在筆者看來,這篇論文直言不諱地指出了大數據系統的不足,時至今日仍非常有指導意義。而此后的十多年,也正是大數據系統逐漸完善彌補這些缺陷的過程,比如 Hive/Spark 填補了高級編程模型的空白,Parquet/ORC 等存儲格式給文件添加了索引,如今的數據湖又在實現缺失的 ACID 事務特性。不過值得一提的是,這些批評是對于通用數據庫場景而言,因為搜索引擎場景針對的是無結構化/非結構化數據,而且 Google 搜索本身就是一個巨大的倒排索引(因此無需額外索引)。
由于大數據系統特性上的種種不足和技術棧的獨立性,大數據在過去的十多年中雖然發展迅猛,各種項目百花齊放,但應用場景仍很大程度上局限在數據倉庫、機器學習等數據準確性要求沒有那么高的場景下。其中很多項目也在設計之初就定位在某些細分應用場景而不是通用場景,比如 Hive 定位為數據倉庫,Storm 定位為對于離線數據倉庫的實時增量補充[5]。雖然這可以視為支持大數據量級而做的 trade-off,但客觀上也造成了大數據生態圈的非常復雜,要完整地用好大數據,通常要引入至少十余個組件,無論對于大數據團隊還是用戶而言都有較高的門檻。
02、現在:百花齊放與融合統一
所謂天下大勢分久必合,一方面大數據生態中各類組件獨立的開發使用成本在業務穩定后已經成為不可小覷的開支,另一方面技術發展也使得不少組件有共享底層設施或技術棧的基礎,因此 “融合” 將是當下最為明顯的趨勢,具體分為幾個方向: 計算的流批一體、存儲的流批一體、在離線服務混部、HTAP。
1.計算的流批一體
計算的流批一體指的是用同一套計算框架同時來實現流計算和批計算,目標是解決 Lambda 架構離線批處理和實時流處理兩個不同編程模型的重復數據管道的問題。
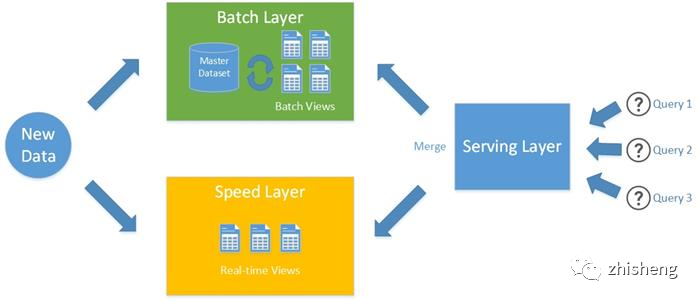 之所以會形成這樣的架構,主要原因是實時流計算發展早期無法提供準確一次的語義(Exactly-Once Semantics),在出現異常重試或數據延遲的情況下很容易導致數據少算或多算,因此需要依賴成熟可靠的離線批計算來定時修正數據。兩者在數據準確性上的差別主要來源于:離線批計算的數據是有界的(因此不用考慮數據是否完整)且允許較高延遲,因而幾乎不需要在數據準確性和延遲間做 trade-off;而實時流計算非常依賴輸入數據的低延遲,如果某個時間點產生的業務數據沒有及時被處理,那么它很可能被錯誤地算入下個統計計算窗口,可能導致前后兩個窗口的數據都不準確。
然而,2015 年 Google Dataflow Model 論文的發布[6]厘清了流處理和批處理的對立統一的關系,即批處理是流處理的特例,這為流批一體的大趨勢奠定了基礎。本文不打算過于深入 Dataflow Model 內容,簡單來說,論文引入了對于流處理至關重要的兩個概念:Watermark 和 Accumulation Mode(結果累積模式)。Watermark 由數據本身的業務時間提取而成(這被稱為 Event Time 時間特性),表示對輸入數據的業務時間的估計。依據 Watermark 而不是數據處理時間來觸發計算,這樣可以很大程度上解決流計算對延遲的依賴問題。另一方面,Accumulation Mode 定義了流計算不同執行產生的結果之間的關系,從而使得流計算可以先輸出不完整的中間結果,然后再逐步修正,最終收斂至準確結果。
在開源界,最早采用流批一體計算模型的計算框架 Flink/Beam 等,在經過幾年的迭代后流批一體已經逐漸達到生產可用,并陸續在前沿的公司落地。由于流批一體涉及到大量業務改造,在目前 Lambda 架構已經穩定運行多年的情況下,推動存量業務的改造的主要動力來源有:
降本增效。避免同時建設兩套數據管道的機器和人力成本。
對齊口徑。批處理的 schema 與流處理的 schema 可能存在不一致,比如同一個指標在批處理可能是天粒度,而流處理是分鐘粒度。這樣的不一致導致同時使用流和批的結果時容易出錯。
值得注意的是,流批一體并不是將 Lambda 架構中的離線管道改為與實時管道相同的引擎,并與之前一樣雙跑,而是令作業可以靈活在兩種模式上自由切換。通常來說,對延遲不敏感的業務可以用批的模式執行來提高資源利用率,而當業務變為延遲敏感時可以無縫切換為實時流處理模式。而在需要修正實時計算結果時,也可以直接采用 Kappa 架構[7]的方式復制一個作業以批模式來重刷部分數據。
2.存儲的流批一體
眾所周知,批處理中常讀寫文件系統,用文件作為存儲抽象;而流處理中常讀寫消息隊列,用隊列作為存儲抽象。在 Lambda 架構中,我們常常要將同時數據寫入 HDFS、S3 等文件系統或對象存儲供批處理使用,并寫入 Kafka 等消息隊列供流處理使用。盡管消息隊列通過只保留最近一段時間的數據來減少數據存儲成本,但這樣兩套系統的冗余仍造成很大的機器資源開銷和人力資源成本。在計算的流批一體大趨勢下,存儲的流批一體的推進自然也是順水推舟。
不過不同于計算有 Dataflow Model 這樣能讓業界達成 “批處理是流處理特例” 共識的重量級論文,存儲的流批一體仍處在基于文件系統和基于消息隊列兩種流派不相伯仲的狀況。基于文件來實現隊列特性的代表是 Iceberg/Hudi/DeltaLake 等數據湖,而以隊列來實現文件特性的代表是 Pulsar/Prevega 等新型消息隊列系統。
在筆者看來,文件存儲和隊列存儲經過一定的改進都可以滿足流批一體的需求,比如 Pulsar 支持將數據歸檔到分級存儲并可選擇 Segment(文件) API 或 Message(隊列) API 來讀取,而 Iceberg 支持文件的批量讀取或流式地監聽文件。然而結合計算的流批一體而言,兩者在寫入更新 API 方面有根本的不同,并且該不同點進一步導致了兩者的許多不同特性:
更新方式。雖然文件和隊列在大數據場景下通常都是以 Append 方式寫入,但文件支持對已經寫入數據的更新,而隊列則不允許直接更新,而是通過寫入新數據加 Compact 刪除舊數據的方式來間接更新。這意味著在批處理中讀寫隊列或在流處理中讀寫文件都有一些不自然(下文會詳細說明)。在數據湖等基于文件的存儲中,流式讀取通常以監聽 Changelog 的方式實現;而在基于隊列的存儲中,批處理要重算更新結果,則無法直接刪除或覆蓋之前已經寫入隊列的結果,要么轉為 Changelog 要么重建一個新隊列。版本控制。由于更新方式的不同,文件中的數據是可變的,而隊列中的數據是不可變的。文件表示某個時間點的狀態,因此數據湖需要版本控制以增加回溯的功能;而相對地,隊列則表示一段時間內狀態變化的事件,本來有 Event Sourcing 的能力,因此不需要版本控制。并行寫入。文件有唯一的寫鎖,只允許單個進程寫入。數據湖通常以整個目錄作為一個表暴露給用戶,如果有多并行寫入,則在該目錄下為每個并行進程新增基于文件的快照進行隔離(MVCC)。而相對地,隊列本來就支持并行寫入,因此無需快照隔離。其實這個差異也是由于兩者不同的更新方式導致的,因為隊列 Append-Only 的方式保證了并發寫入也不會導致數據丟失,而文件則不然。
通過上述的分析,相信不少讀者已經隱約感覺到:基于文件的存儲類似流表二象性中的表,適合用于保存可以被查詢的可變狀態(計算的最終結果或中間結果),而基于隊列的存儲類似表示流表二象性中的流,適合用于保存被流計算引擎讀取的事件流(Changelog 數據)。
之所以會形成這樣的架構,主要原因是實時流計算發展早期無法提供準確一次的語義(Exactly-Once Semantics),在出現異常重試或數據延遲的情況下很容易導致數據少算或多算,因此需要依賴成熟可靠的離線批計算來定時修正數據。兩者在數據準確性上的差別主要來源于:離線批計算的數據是有界的(因此不用考慮數據是否完整)且允許較高延遲,因而幾乎不需要在數據準確性和延遲間做 trade-off;而實時流計算非常依賴輸入數據的低延遲,如果某個時間點產生的業務數據沒有及時被處理,那么它很可能被錯誤地算入下個統計計算窗口,可能導致前后兩個窗口的數據都不準確。
然而,2015 年 Google Dataflow Model 論文的發布[6]厘清了流處理和批處理的對立統一的關系,即批處理是流處理的特例,這為流批一體的大趨勢奠定了基礎。本文不打算過于深入 Dataflow Model 內容,簡單來說,論文引入了對于流處理至關重要的兩個概念:Watermark 和 Accumulation Mode(結果累積模式)。Watermark 由數據本身的業務時間提取而成(這被稱為 Event Time 時間特性),表示對輸入數據的業務時間的估計。依據 Watermark 而不是數據處理時間來觸發計算,這樣可以很大程度上解決流計算對延遲的依賴問題。另一方面,Accumulation Mode 定義了流計算不同執行產生的結果之間的關系,從而使得流計算可以先輸出不完整的中間結果,然后再逐步修正,最終收斂至準確結果。
在開源界,最早采用流批一體計算模型的計算框架 Flink/Beam 等,在經過幾年的迭代后流批一體已經逐漸達到生產可用,并陸續在前沿的公司落地。由于流批一體涉及到大量業務改造,在目前 Lambda 架構已經穩定運行多年的情況下,推動存量業務的改造的主要動力來源有:
降本增效。避免同時建設兩套數據管道的機器和人力成本。
對齊口徑。批處理的 schema 與流處理的 schema 可能存在不一致,比如同一個指標在批處理可能是天粒度,而流處理是分鐘粒度。這樣的不一致導致同時使用流和批的結果時容易出錯。
值得注意的是,流批一體并不是將 Lambda 架構中的離線管道改為與實時管道相同的引擎,并與之前一樣雙跑,而是令作業可以靈活在兩種模式上自由切換。通常來說,對延遲不敏感的業務可以用批的模式執行來提高資源利用率,而當業務變為延遲敏感時可以無縫切換為實時流處理模式。而在需要修正實時計算結果時,也可以直接采用 Kappa 架構[7]的方式復制一個作業以批模式來重刷部分數據。
2.存儲的流批一體
眾所周知,批處理中常讀寫文件系統,用文件作為存儲抽象;而流處理中常讀寫消息隊列,用隊列作為存儲抽象。在 Lambda 架構中,我們常常要將同時數據寫入 HDFS、S3 等文件系統或對象存儲供批處理使用,并寫入 Kafka 等消息隊列供流處理使用。盡管消息隊列通過只保留最近一段時間的數據來減少數據存儲成本,但這樣兩套系統的冗余仍造成很大的機器資源開銷和人力資源成本。在計算的流批一體大趨勢下,存儲的流批一體的推進自然也是順水推舟。
不過不同于計算有 Dataflow Model 這樣能讓業界達成 “批處理是流處理特例” 共識的重量級論文,存儲的流批一體仍處在基于文件系統和基于消息隊列兩種流派不相伯仲的狀況。基于文件來實現隊列特性的代表是 Iceberg/Hudi/DeltaLake 等數據湖,而以隊列來實現文件特性的代表是 Pulsar/Prevega 等新型消息隊列系統。
在筆者看來,文件存儲和隊列存儲經過一定的改進都可以滿足流批一體的需求,比如 Pulsar 支持將數據歸檔到分級存儲并可選擇 Segment(文件) API 或 Message(隊列) API 來讀取,而 Iceberg 支持文件的批量讀取或流式地監聽文件。然而結合計算的流批一體而言,兩者在寫入更新 API 方面有根本的不同,并且該不同點進一步導致了兩者的許多不同特性:
更新方式。雖然文件和隊列在大數據場景下通常都是以 Append 方式寫入,但文件支持對已經寫入數據的更新,而隊列則不允許直接更新,而是通過寫入新數據加 Compact 刪除舊數據的方式來間接更新。這意味著在批處理中讀寫隊列或在流處理中讀寫文件都有一些不自然(下文會詳細說明)。在數據湖等基于文件的存儲中,流式讀取通常以監聽 Changelog 的方式實現;而在基于隊列的存儲中,批處理要重算更新結果,則無法直接刪除或覆蓋之前已經寫入隊列的結果,要么轉為 Changelog 要么重建一個新隊列。版本控制。由于更新方式的不同,文件中的數據是可變的,而隊列中的數據是不可變的。文件表示某個時間點的狀態,因此數據湖需要版本控制以增加回溯的功能;而相對地,隊列則表示一段時間內狀態變化的事件,本來有 Event Sourcing 的能力,因此不需要版本控制。并行寫入。文件有唯一的寫鎖,只允許單個進程寫入。數據湖通常以整個目錄作為一個表暴露給用戶,如果有多并行寫入,則在該目錄下為每個并行進程新增基于文件的快照進行隔離(MVCC)。而相對地,隊列本來就支持并行寫入,因此無需快照隔離。其實這個差異也是由于兩者不同的更新方式導致的,因為隊列 Append-Only 的方式保證了并發寫入也不會導致數據丟失,而文件則不然。
通過上述的分析,相信不少讀者已經隱約感覺到:基于文件的存儲類似流表二象性中的表,適合用于保存可以被查詢的可變狀態(計算的最終結果或中間結果),而基于隊列的存儲類似表示流表二象性中的流,適合用于保存被流計算引擎讀取的事件流(Changelog 數據)。
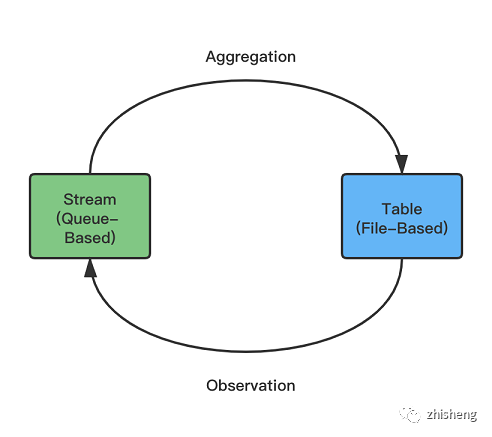 雖然流表二象性能使得兩者可以交替使用,但若使用不當會導致數據在流表兩種狀態間進行不必要的轉換,并給下游業務造成額外的麻煩。具體來講,如果文件系統中存的是 Changelog 數據,那么下游進行流式讀取(監聽)時,讀到的是 Changelog 的 Changelog,完全不合理。相對地,如果消息隊列存的是非 Changelog 數據,那么該隊列則丟失了更新的能力,任何更新都會導致消息不同版本的同時存在。由于目前 Changelog 類型一般由 CDC 或者流計算的聚合、Join 產生,還未推廣到一般的 MQ 使用場景,所以后一種問題更常發生。但筆者認為,Changelog 是更加流原生的格式,未來大概會標準化并普及到隊列存儲中,目前非 Changelog 的數據則可以被看作是 Append-Only 業務的特例。
上述的結論可以被應用到當前熱門的實時數倉建設中。除了 Lambda 架構,當前實時數倉架構主要有 Kappa 架構和實時 OLAP 變體兩種[9],無論哪種通常都使用 Kafka/Pulsar 等 MQ 作為 ODS/DWD/DWS 等中間層的存儲,OLAP 數據庫或 OLTP 數據庫作為 ADS 應用層的儲存。這樣的架構主要問題在于不夠靈活,比如若想直接基于 DWD 層做一些 Ad-hoc 分析,那么常要將 DWD 層 MQ 中的數據再導出到數據庫再做查詢。
雖然流表二象性能使得兩者可以交替使用,但若使用不當會導致數據在流表兩種狀態間進行不必要的轉換,并給下游業務造成額外的麻煩。具體來講,如果文件系統中存的是 Changelog 數據,那么下游進行流式讀取(監聽)時,讀到的是 Changelog 的 Changelog,完全不合理。相對地,如果消息隊列存的是非 Changelog 數據,那么該隊列則丟失了更新的能力,任何更新都會導致消息不同版本的同時存在。由于目前 Changelog 類型一般由 CDC 或者流計算的聚合、Join 產生,還未推廣到一般的 MQ 使用場景,所以后一種問題更常發生。但筆者認為,Changelog 是更加流原生的格式,未來大概會標準化并普及到隊列存儲中,目前非 Changelog 的數據則可以被看作是 Append-Only 業務的特例。
上述的結論可以被應用到當前熱門的實時數倉建設中。除了 Lambda 架構,當前實時數倉架構主要有 Kappa 架構和實時 OLAP 變體兩種[9],無論哪種通常都使用 Kafka/Pulsar 等 MQ 作為 ODS/DWD/DWS 等中間層的存儲,OLAP 數據庫或 OLTP 數據庫作為 ADS 應用層的儲存。這樣的架構主要問題在于不夠靈活,比如若想直接基于 DWD 層做一些 Ad-hoc 分析,那么常要將 DWD 層 MQ 中的數據再導出到數據庫再做查詢。
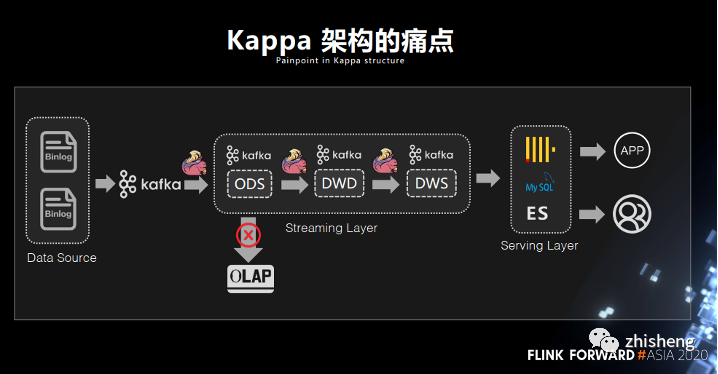 可能有讀者會問,如果使用 Flink 直接讀 MQ 數據來算呢?其實是可以的,因為像 Pulsar 也提供了無限期的存儲,但效率會比較低,主要原因是 MQ 無法提供索引來實現謂詞下推等優化[10],另外經過聚合或者 Join 的數據是 Changelog 格式,數據流中會包含舊版本的冗余數據。因此業界有新的趨勢是用 Iceberg 等數據湖來代替 MQ 作為數倉中間層的存儲,這樣的優點是能比較好地對接離線數倉及其長久以來的業務模式,而代價則是數據延遲可能變為近實時。以本文 “文件適合存儲狀態” 的觀點來講,實時數倉中需要被業務查詢的表的確更適合用文件存儲,因為業務需要的是狀態,而不關心變更歷史。
3.在離線混部
在離線混部指的是將在線業務與大數據場景的實時、離線業務混合部署在相同的物理集群上,目的是提高機器的利用率。由于歷史原因,在線業務和大數據業務的技術棧是相對獨立的,因而理所當然地分開部署: 在線業務使用為 k8s/Mesos 代表的集群管理器,而大數據業務通常使用 Hadoop 生態原生的 YARN 作為集群管理器。然而隨著集群規模的擴大,資源利用率不足的問題日益突顯,例如通常 CPU 平均占用不足 20%。解決問題的最佳辦法便是打破不同業務獨立集群的邊界實現混部,并利用業務資源的潮汐現象和優先級進行動態的資源分配。實際上很多公司在離線混部已經有多年的探索,而最近一兩年 k8s 的迅猛發展大大加速了業務(包括大數據)上云的進度,因而在離線混部再次成為熱點。
在離線混部技術的難點主要是統一集群管理器、資源隔離和資源調度這幾點,下文逐點展開。
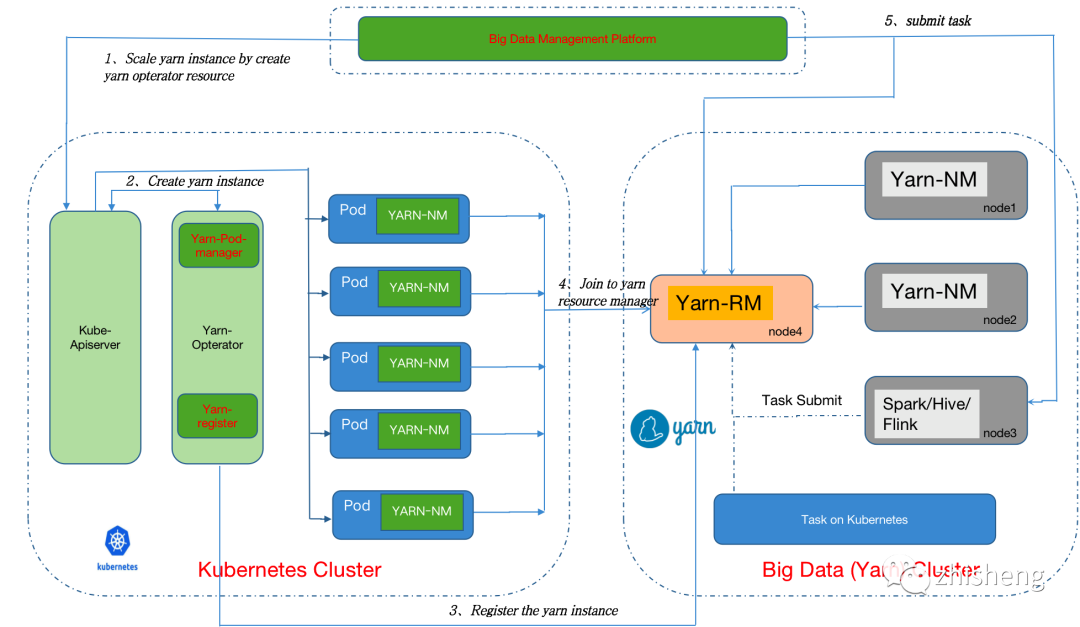
首先,統一在離線的集群管理器是混部的基礎。目前大多數公司是 k8s 與 YARN 并存的狀態,但在云原生的大趨勢下,大數據組件也逐步對 k8s 提供頭等的支持,看起來 k8s 一統集群資源只是時間問題。不過 k8s 的要做到這點也絕非一路平坦,一是 k8s 的一級調度設計并不能很好地滿足很多批計算作業的復雜調度,二是 k8s 當前能掌控的集群規模一般在 5000 節點左右,比起 YARN 差了一個量級[11]。因此在當前階段,業界大多是選擇 YARN on k8s 的方式來漸進式地遷移。常見的做法是在 k8s pod 里啟動 NM,讓 YARN 部分 NM 節點運行在 k8s 上。
可能有讀者會問,如果使用 Flink 直接讀 MQ 數據來算呢?其實是可以的,因為像 Pulsar 也提供了無限期的存儲,但效率會比較低,主要原因是 MQ 無法提供索引來實現謂詞下推等優化[10],另外經過聚合或者 Join 的數據是 Changelog 格式,數據流中會包含舊版本的冗余數據。因此業界有新的趨勢是用 Iceberg 等數據湖來代替 MQ 作為數倉中間層的存儲,這樣的優點是能比較好地對接離線數倉及其長久以來的業務模式,而代價則是數據延遲可能變為近實時。以本文 “文件適合存儲狀態” 的觀點來講,實時數倉中需要被業務查詢的表的確更適合用文件存儲,因為業務需要的是狀態,而不關心變更歷史。
3.在離線混部
在離線混部指的是將在線業務與大數據場景的實時、離線業務混合部署在相同的物理集群上,目的是提高機器的利用率。由于歷史原因,在線業務和大數據業務的技術棧是相對獨立的,因而理所當然地分開部署: 在線業務使用為 k8s/Mesos 代表的集群管理器,而大數據業務通常使用 Hadoop 生態原生的 YARN 作為集群管理器。然而隨著集群規模的擴大,資源利用率不足的問題日益突顯,例如通常 CPU 平均占用不足 20%。解決問題的最佳辦法便是打破不同業務獨立集群的邊界實現混部,并利用業務資源的潮汐現象和優先級進行動態的資源分配。實際上很多公司在離線混部已經有多年的探索,而最近一兩年 k8s 的迅猛發展大大加速了業務(包括大數據)上云的進度,因而在離線混部再次成為熱點。
在離線混部技術的難點主要是統一集群管理器、資源隔離和資源調度這幾點,下文逐點展開。
首先,統一在離線的集群管理器是混部的基礎。目前大多數公司是 k8s 與 YARN 并存的狀態,但在云原生的大趨勢下,大數據組件也逐步對 k8s 提供頭等的支持,看起來 k8s 一統集群資源只是時間問題。不過 k8s 的要做到這點也絕非一路平坦,一是 k8s 的一級調度設計并不能很好地滿足很多批計算作業的復雜調度,二是 k8s 當前能掌控的集群規模一般在 5000 節點左右,比起 YARN 差了一個量級[11]。因此在當前階段,業界大多是選擇 YARN on k8s 的方式來漸進式地遷移。常見的做法是在 k8s pod 里啟動 NM,讓 YARN 部分 NM 節點運行在 k8s 上。
 然后,資源隔離是混部的核心。雖然 k8s 提供資源管理,但是僅限于 CPU、內存兩個維度,而網絡和磁盤 IO 卻暫未納入考慮[12]。這對于在混部大數據業務而言顯然是不夠的,因為大數據業務可以很輕松地將機器的網絡或磁盤打滿,嚴重影響在線業務。要達到生產的資源隔離,通常需要 Linux 內核級別的支持,這超出本文的范圍和筆者的知識儲備,不再詳述。
最后,資源調度是服務質量的保證。調度器需要考慮物理節點的資源異構、同類業務充分打散分布和業務的部署偏好來優化調度,優化效率并最大程度避免相互干擾。此外,集群調度器會按照優先級來進行資源超發。在業務低峰期,空閑的資源可以用于跑優先級低、延遲不敏感的離線作業,然而在業務出現突發流量或發現在線作業受到離線作業干擾時,集群調度器需要快速讓離線作業退出并讓出資源。
4.HTAP
HTAP 全稱是 Hybrid Transactional Analytical Processing (混合事務分析處理),即同時支持在線事務查詢和分析查詢。前文所說的計算和存儲的流批一體是實時和離線技術棧上的融合,在離線混部是大數據業務與在線業務運維管理上的融合,而 HTAP 就是最終的大數據和在線業務技術棧上的融合。自 2014 年 Gartner 提出該概念后,HTAP 成為了數據庫領域最為熱門的方向。除了簡化 OLTP 和 OLAP 兩套技術棧的復雜架構外,HTAP 還有一個重要的需求背景: 隨著數據場景從企業內部決策支持,到用作為線上增值服務的算法模型輸入(比如推薦、廣告),再到直接作為面向用戶的數據服務(比如淘寶生意參謀、滴滴行車軌跡等),OLTP 和 OLAP 的邊界正變得越來越模糊。
HTAP 從架構來看分為兩類: 單系統同時服務于 OLTP 和 OLAP,或有兩套系統分別服務于 OLTP 和 OLAP。現在業界比較熱門的 TiDB、OceanBase 和 Google 的 F1 Lightning 都屬于后者。在這類系統中,OLTP 和 OLAP 分別有獨立的存儲和計算引擎,并依靠內建的同步機制來將 OLTP 系統中的行存數據同步到 OLAP 系統轉為適合分析業務的列存數據。在此之上,查詢優化器對外提供統一的查詢入口,將不同類型的查詢分別路由到合適的系統中。
然后,資源隔離是混部的核心。雖然 k8s 提供資源管理,但是僅限于 CPU、內存兩個維度,而網絡和磁盤 IO 卻暫未納入考慮[12]。這對于在混部大數據業務而言顯然是不夠的,因為大數據業務可以很輕松地將機器的網絡或磁盤打滿,嚴重影響在線業務。要達到生產的資源隔離,通常需要 Linux 內核級別的支持,這超出本文的范圍和筆者的知識儲備,不再詳述。
最后,資源調度是服務質量的保證。調度器需要考慮物理節點的資源異構、同類業務充分打散分布和業務的部署偏好來優化調度,優化效率并最大程度避免相互干擾。此外,集群調度器會按照優先級來進行資源超發。在業務低峰期,空閑的資源可以用于跑優先級低、延遲不敏感的離線作業,然而在業務出現突發流量或發現在線作業受到離線作業干擾時,集群調度器需要快速讓離線作業退出并讓出資源。
4.HTAP
HTAP 全稱是 Hybrid Transactional Analytical Processing (混合事務分析處理),即同時支持在線事務查詢和分析查詢。前文所說的計算和存儲的流批一體是實時和離線技術棧上的融合,在離線混部是大數據業務與在線業務運維管理上的融合,而 HTAP 就是最終的大數據和在線業務技術棧上的融合。自 2014 年 Gartner 提出該概念后,HTAP 成為了數據庫領域最為熱門的方向。除了簡化 OLTP 和 OLAP 兩套技術棧的復雜架構外,HTAP 還有一個重要的需求背景: 隨著數據場景從企業內部決策支持,到用作為線上增值服務的算法模型輸入(比如推薦、廣告),再到直接作為面向用戶的數據服務(比如淘寶生意參謀、滴滴行車軌跡等),OLTP 和 OLAP 的邊界正變得越來越模糊。
HTAP 從架構來看分為兩類: 單系統同時服務于 OLTP 和 OLAP,或有兩套系統分別服務于 OLTP 和 OLAP。現在業界比較熱門的 TiDB、OceanBase 和 Google 的 F1 Lightning 都屬于后者。在這類系統中,OLTP 和 OLAP 分別有獨立的存儲和計算引擎,并依靠內建的同步機制來將 OLTP 系統中的行存數據同步到 OLAP 系統轉為適合分析業務的列存數據。在此之上,查詢優化器對外提供統一的查詢入口,將不同類型的查詢分別路由到合適的系統中。
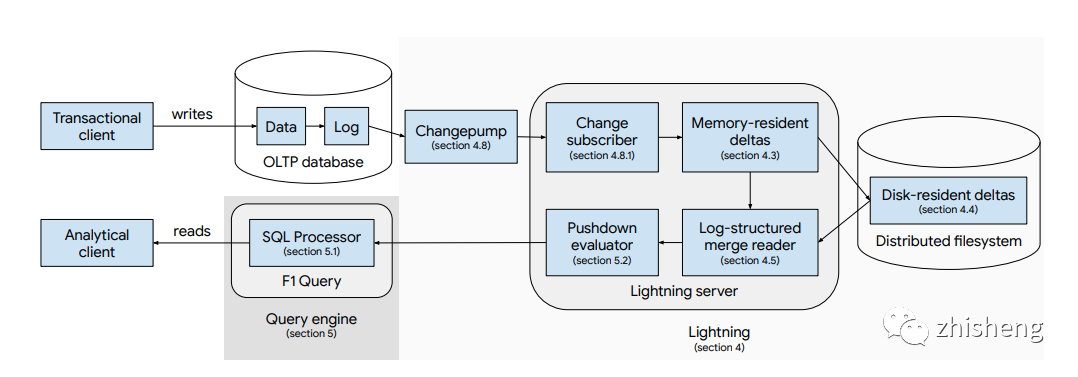 比起傳統的基于 Hadoop 生態的數據倉庫,HTAP 的優點是:
內置可靠的數據同步機制,避免建立 OLTP 庫到數據倉庫的復雜 ETL 管道,同時也提高了數據一致性(比如 TiDB 和 F1 Lightning 都提供與 OLTP 一致的可重復讀一致性)。
對用戶友好的統一查詢接口,屏蔽了底層引擎的復雜性,大大降低了 OLAP 的門檻。這使得在有授權的情況下,線上業務團隊能利用 OLAP 進行輕量級數據分析,而數據分析團隊也能利用 OLTP 進行快速的點查。
數據安全性更有保障。將數據在不同組件間移動容易造成權限不一致和安全漏洞,而 HTAP 可以復用 OLTP 的數據權限和避免數據跨組件訪問來避免這些問題。
雖然 HTAP 的愿景非常美好,但要構建經得起業務檢驗的 HTAP 系統并不容易。數據庫和大數據領域先后有多次嘗試,不過目前算得上成功的案例屈指可數,其主要難點在于:
OLTP 和 OLAP 資源的隔離。由于 OLAP 常包含一些資源密集的復雜查詢,OLTP 和 OLAP 公用的組件很容易產生資源競爭,從而干擾優先級更高的 OLTP 查詢。在早些年的案例中,共享計算和存儲的 HTAP 都不能獲得很好的效果,因此最近的 HTAP 數據庫都在硬件級別進行兩者負載的隔離,也就是獨立的存儲和計算。
數據同步機制如何確保數據一致性和新鮮度(freshness)。不同于基于 Hadoop 的數據倉庫通常允許小時級別的數據延遲和不一致窗口,HTAP 通常承諾強一致性以保證一個查詢無論被路由到 OLTP 系統還是 OLAP 系統都能獲得一致結果,這對數據同步機制的性能和容錯性都提出很高的要求。目前在 HTAP 領域稱得上 State of the art 的兩個數據庫里,F1 Lightning 使用無入侵的 CDC 方式進行同步,TiDB 基于 Raft 算法進行數據復制。前者松耦合,但實現比較復雜;后者更加簡潔優雅,但會受 OLTP 設計的約束,比如復制的數據塊大小需要與 OLTP 一致[16]。
淺談大數據的過去、現在和未來
如何利有機結合 OLTP 和 OLAP 工作負載。目前的 HTAP 像同一個門面后的兩套獨立系統,一個查詢要么交給 OLTP 處理,要么交給 OLAP 處理,并沒有產生 1 + 1 > 2 的化學反應。IBM 指出,真正的 OLAP 是在同一個事務里高效地處理 OLTP 和 OLAP 兩種工作負載[15]。要做到這點,靠數據同步的 HTAP 架構大概難以做到,需要從分布式事務算法層面來解決。
盡管 HTAP 還未被廣泛應用,但可以預見未來將在很大程度上影響數據倉庫架構。在數據規模不大、分析需求簡單的場景下,HTAP 將成為最為流行的解決方案。
03、未來:回歸本質
“融合” 是大數據當前發展的大勢,這點從歷史的發展規律角度可以窺見其必然性。對于新出現的技術挑戰,在最初的探索期各類解決方案總是層出不窮,其中采用 Greenfield 方式的解決方案可能會將已有的基礎推倒重來,相比原有技術帶來一定的退化(Regression)。退化限制了新技術的應用場景,導致新舊兩種技術的雙軌制,但只要核心功能沒有太大變化,這樣的割裂這往往只是暫時的。
回顧大數據的發展歷史,“大數據” 一詞原本用于描述數據規模、多樣性和處理性能給數據管理帶來的挑戰,而后續被用于描述為處理這類問題而構建的數據系統,即 “大數據系統”。由于這類系統基于與傳統數據不同的基礎構建,并舍棄后者標配的事務特性,導致難以應用到線上業務,通常只用于數據倉庫、機器學習等對數據延遲、數據準確性要求稍微低一點的場景,而這類業務場景又逐漸被稱為 “大數據業務”。
然而,大數據技術本質是數據密集型的分布式系統,而隨著分布式系統的發展和普及,大數據系統在功能特性和業務場景的限制終將被打破,與新出現的以 Spanner 為代表的 NewSQL 分布式數據庫并無明顯界限。屆時,”大數據” 一詞也許會和很多 buzzword 一樣逐漸消失在歷史的長河,回歸到通用的分布式系統的本質。水平擴展、優秀容錯性、高可用的分布式特性將成為各種系統的標配,無論在 OLTP 或者 OLAP 場景。
比起傳統的基于 Hadoop 生態的數據倉庫,HTAP 的優點是:
內置可靠的數據同步機制,避免建立 OLTP 庫到數據倉庫的復雜 ETL 管道,同時也提高了數據一致性(比如 TiDB 和 F1 Lightning 都提供與 OLTP 一致的可重復讀一致性)。
對用戶友好的統一查詢接口,屏蔽了底層引擎的復雜性,大大降低了 OLAP 的門檻。這使得在有授權的情況下,線上業務團隊能利用 OLAP 進行輕量級數據分析,而數據分析團隊也能利用 OLTP 進行快速的點查。
數據安全性更有保障。將數據在不同組件間移動容易造成權限不一致和安全漏洞,而 HTAP 可以復用 OLTP 的數據權限和避免數據跨組件訪問來避免這些問題。
雖然 HTAP 的愿景非常美好,但要構建經得起業務檢驗的 HTAP 系統并不容易。數據庫和大數據領域先后有多次嘗試,不過目前算得上成功的案例屈指可數,其主要難點在于:
OLTP 和 OLAP 資源的隔離。由于 OLAP 常包含一些資源密集的復雜查詢,OLTP 和 OLAP 公用的組件很容易產生資源競爭,從而干擾優先級更高的 OLTP 查詢。在早些年的案例中,共享計算和存儲的 HTAP 都不能獲得很好的效果,因此最近的 HTAP 數據庫都在硬件級別進行兩者負載的隔離,也就是獨立的存儲和計算。
數據同步機制如何確保數據一致性和新鮮度(freshness)。不同于基于 Hadoop 的數據倉庫通常允許小時級別的數據延遲和不一致窗口,HTAP 通常承諾強一致性以保證一個查詢無論被路由到 OLTP 系統還是 OLAP 系統都能獲得一致結果,這對數據同步機制的性能和容錯性都提出很高的要求。目前在 HTAP 領域稱得上 State of the art 的兩個數據庫里,F1 Lightning 使用無入侵的 CDC 方式進行同步,TiDB 基于 Raft 算法進行數據復制。前者松耦合,但實現比較復雜;后者更加簡潔優雅,但會受 OLTP 設計的約束,比如復制的數據塊大小需要與 OLTP 一致[16]。
淺談大數據的過去、現在和未來
如何利有機結合 OLTP 和 OLAP 工作負載。目前的 HTAP 像同一個門面后的兩套獨立系統,一個查詢要么交給 OLTP 處理,要么交給 OLAP 處理,并沒有產生 1 + 1 > 2 的化學反應。IBM 指出,真正的 OLAP 是在同一個事務里高效地處理 OLTP 和 OLAP 兩種工作負載[15]。要做到這點,靠數據同步的 HTAP 架構大概難以做到,需要從分布式事務算法層面來解決。
盡管 HTAP 還未被廣泛應用,但可以預見未來將在很大程度上影響數據倉庫架構。在數據規模不大、分析需求簡單的場景下,HTAP 將成為最為流行的解決方案。
03、未來:回歸本質
“融合” 是大數據當前發展的大勢,這點從歷史的發展規律角度可以窺見其必然性。對于新出現的技術挑戰,在最初的探索期各類解決方案總是層出不窮,其中采用 Greenfield 方式的解決方案可能會將已有的基礎推倒重來,相比原有技術帶來一定的退化(Regression)。退化限制了新技術的應用場景,導致新舊兩種技術的雙軌制,但只要核心功能沒有太大變化,這樣的割裂這往往只是暫時的。
回顧大數據的發展歷史,“大數據” 一詞原本用于描述數據規模、多樣性和處理性能給數據管理帶來的挑戰,而后續被用于描述為處理這類問題而構建的數據系統,即 “大數據系統”。由于這類系統基于與傳統數據不同的基礎構建,并舍棄后者標配的事務特性,導致難以應用到線上業務,通常只用于數據倉庫、機器學習等對數據延遲、數據準確性要求稍微低一點的場景,而這類業務場景又逐漸被稱為 “大數據業務”。
然而,大數據技術本質是數據密集型的分布式系統,而隨著分布式系統的發展和普及,大數據系統在功能特性和業務場景的限制終將被打破,與新出現的以 Spanner 為代表的 NewSQL 分布式數據庫并無明顯界限。屆時,”大數據” 一詞也許會和很多 buzzword 一樣逐漸消失在歷史的長河,回歸到通用的分布式系統的本質。水平擴展、優秀容錯性、高可用的分布式特性將成為各種系統的標配,無論在 OLTP 或者 OLAP 場景。
之所以會形成這樣的架構,主要原因是實時流計算發展早期無法提供準確一次的語義(Exactly-Once Semantics),在出現異常重試或數據延遲的情況下很容易導致數據少算或多算,因此需要依賴成熟可靠的離線批計算來定時修正數據。兩者在數據準確性上的差別主要來源于:離線批計算的數據是有界的(因此不用考慮數據是否完整)且允許較高延遲,因而幾乎不需要在數據準確性和延遲間做 trade-off;而實時流計算非常依賴輸入數據的低延遲,如果某個時間點產生的業務數據沒有及時被處理,那么它很可能被錯誤地算入下個統計計算窗口,可能導致前后兩個窗口的數據都不準確。
然而,2015 年 Google Dataflow Model 論文的發布[6]厘清了流處理和批處理的對立統一的關系,即批處理是流處理的特例,這為流批一體的大趨勢奠定了基礎。本文不打算過于深入 Dataflow Model 內容,簡單來說,論文引入了對于流處理至關重要的兩個概念:Watermark 和 Accumulation Mode(結果累積模式)。Watermark 由數據本身的業務時間提取而成(這被稱為 Event Time 時間特性),表示對輸入數據的業務時間的估計。依據 Watermark 而不是數據處理時間來觸發計算,這樣可以很大程度上解決流計算對延遲的依賴問題。另一方面,Accumulation Mode 定義了流計算不同執行產生的結果之間的關系,從而使得流計算可以先輸出不完整的中間結果,然后再逐步修正,最終收斂至準確結果。
在開源界,最早采用流批一體計算模型的計算框架 Flink/Beam 等,在經過幾年的迭代后流批一體已經逐漸達到生產可用,并陸續在前沿的公司落地。由于流批一體涉及到大量業務改造,在目前 Lambda 架構已經穩定運行多年的情況下,推動存量業務的改造的主要動力來源有:
降本增效。避免同時建設兩套數據管道的機器和人力成本。
對齊口徑。批處理的 schema 與流處理的 schema 可能存在不一致,比如同一個指標在批處理可能是天粒度,而流處理是分鐘粒度。這樣的不一致導致同時使用流和批的結果時容易出錯。
值得注意的是,流批一體并不是將 Lambda 架構中的離線管道改為與實時管道相同的引擎,并與之前一樣雙跑,而是令作業可以靈活在兩種模式上自由切換。通常來說,對延遲不敏感的業務可以用批的模式執行來提高資源利用率,而當業務變為延遲敏感時可以無縫切換為實時流處理模式。而在需要修正實時計算結果時,也可以直接采用 Kappa 架構[7]的方式復制一個作業以批模式來重刷部分數據。
2.存儲的流批一體
眾所周知,批處理中常讀寫文件系統,用文件作為存儲抽象;而流處理中常讀寫消息隊列,用隊列作為存儲抽象。在 Lambda 架構中,我們常常要將同時數據寫入 HDFS、S3 等文件系統或對象存儲供批處理使用,并寫入 Kafka 等消息隊列供流處理使用。盡管消息隊列通過只保留最近一段時間的數據來減少數據存儲成本,但這樣兩套系統的冗余仍造成很大的機器資源開銷和人力資源成本。在計算的流批一體大趨勢下,存儲的流批一體的推進自然也是順水推舟。
不過不同于計算有 Dataflow Model 這樣能讓業界達成 “批處理是流處理特例” 共識的重量級論文,存儲的流批一體仍處在基于文件系統和基于消息隊列兩種流派不相伯仲的狀況。基于文件來實現隊列特性的代表是 Iceberg/Hudi/DeltaLake 等數據湖,而以隊列來實現文件特性的代表是 Pulsar/Prevega 等新型消息隊列系統。
在筆者看來,文件存儲和隊列存儲經過一定的改進都可以滿足流批一體的需求,比如 Pulsar 支持將數據歸檔到分級存儲并可選擇 Segment(文件) API 或 Message(隊列) API 來讀取,而 Iceberg 支持文件的批量讀取或流式地監聽文件。然而結合計算的流批一體而言,兩者在寫入更新 API 方面有根本的不同,并且該不同點進一步導致了兩者的許多不同特性:
更新方式。雖然文件和隊列在大數據場景下通常都是以 Append 方式寫入,但文件支持對已經寫入數據的更新,而隊列則不允許直接更新,而是通過寫入新數據加 Compact 刪除舊數據的方式來間接更新。這意味著在批處理中讀寫隊列或在流處理中讀寫文件都有一些不自然(下文會詳細說明)。在數據湖等基于文件的存儲中,流式讀取通常以監聽 Changelog 的方式實現;而在基于隊列的存儲中,批處理要重算更新結果,則無法直接刪除或覆蓋之前已經寫入隊列的結果,要么轉為 Changelog 要么重建一個新隊列。版本控制。由于更新方式的不同,文件中的數據是可變的,而隊列中的數據是不可變的。文件表示某個時間點的狀態,因此數據湖需要版本控制以增加回溯的功能;而相對地,隊列則表示一段時間內狀態變化的事件,本來有 Event Sourcing 的能力,因此不需要版本控制。并行寫入。文件有唯一的寫鎖,只允許單個進程寫入。數據湖通常以整個目錄作為一個表暴露給用戶,如果有多并行寫入,則在該目錄下為每個并行進程新增基于文件的快照進行隔離(MVCC)。而相對地,隊列本來就支持并行寫入,因此無需快照隔離。其實這個差異也是由于兩者不同的更新方式導致的,因為隊列 Append-Only 的方式保證了并發寫入也不會導致數據丟失,而文件則不然。
通過上述的分析,相信不少讀者已經隱約感覺到:基于文件的存儲類似流表二象性中的表,適合用于保存可以被查詢的可變狀態(計算的最終結果或中間結果),而基于隊列的存儲類似表示流表二象性中的流,適合用于保存被流計算引擎讀取的事件流(Changelog 數據)。
雖然流表二象性能使得兩者可以交替使用,但若使用不當會導致數據在流表兩種狀態間進行不必要的轉換,并給下游業務造成額外的麻煩。具體來講,如果文件系統中存的是 Changelog 數據,那么下游進行流式讀取(監聽)時,讀到的是 Changelog 的 Changelog,完全不合理。相對地,如果消息隊列存的是非 Changelog 數據,那么該隊列則丟失了更新的能力,任何更新都會導致消息不同版本的同時存在。由于目前 Changelog 類型一般由 CDC 或者流計算的聚合、Join 產生,還未推廣到一般的 MQ 使用場景,所以后一種問題更常發生。但筆者認為,Changelog 是更加流原生的格式,未來大概會標準化并普及到隊列存儲中,目前非 Changelog 的數據則可以被看作是 Append-Only 業務的特例。
上述的結論可以被應用到當前熱門的實時數倉建設中。除了 Lambda 架構,當前實時數倉架構主要有 Kappa 架構和實時 OLAP 變體兩種[9],無論哪種通常都使用 Kafka/Pulsar 等 MQ 作為 ODS/DWD/DWS 等中間層的存儲,OLAP 數據庫或 OLTP 數據庫作為 ADS 應用層的儲存。這樣的架構主要問題在于不夠靈活,比如若想直接基于 DWD 層做一些 Ad-hoc 分析,那么常要將 DWD 層 MQ 中的數據再導出到數據庫再做查詢。
可能有讀者會問,如果使用 Flink 直接讀 MQ 數據來算呢?其實是可以的,因為像 Pulsar 也提供了無限期的存儲,但效率會比較低,主要原因是 MQ 無法提供索引來實現謂詞下推等優化[10],另外經過聚合或者 Join 的數據是 Changelog 格式,數據流中會包含舊版本的冗余數據。因此業界有新的趨勢是用 Iceberg 等數據湖來代替 MQ 作為數倉中間層的存儲,這樣的優點是能比較好地對接離線數倉及其長久以來的業務模式,而代價則是數據延遲可能變為近實時。以本文 “文件適合存儲狀態” 的觀點來講,實時數倉中需要被業務查詢的表的確更適合用文件存儲,因為業務需要的是狀態,而不關心變更歷史。
3.在離線混部
在離線混部指的是將在線業務與大數據場景的實時、離線業務混合部署在相同的物理集群上,目的是提高機器的利用率。由于歷史原因,在線業務和大數據業務的技術棧是相對獨立的,因而理所當然地分開部署: 在線業務使用為 k8s/Mesos 代表的集群管理器,而大數據業務通常使用 Hadoop 生態原生的 YARN 作為集群管理器。然而隨著集群規模的擴大,資源利用率不足的問題日益突顯,例如通常 CPU 平均占用不足 20%。解決問題的最佳辦法便是打破不同業務獨立集群的邊界實現混部,并利用業務資源的潮汐現象和優先級進行動態的資源分配。實際上很多公司在離線混部已經有多年的探索,而最近一兩年 k8s 的迅猛發展大大加速了業務(包括大數據)上云的進度,因而在離線混部再次成為熱點。
在離線混部技術的難點主要是統一集群管理器、資源隔離和資源調度這幾點,下文逐點展開。
首先,統一在離線的集群管理器是混部的基礎。目前大多數公司是 k8s 與 YARN 并存的狀態,但在云原生的大趨勢下,大數據組件也逐步對 k8s 提供頭等的支持,看起來 k8s 一統集群資源只是時間問題。不過 k8s 的要做到這點也絕非一路平坦,一是 k8s 的一級調度設計并不能很好地滿足很多批計算作業的復雜調度,二是 k8s 當前能掌控的集群規模一般在 5000 節點左右,比起 YARN 差了一個量級[11]。因此在當前階段,業界大多是選擇 YARN on k8s 的方式來漸進式地遷移。常見的做法是在 k8s pod 里啟動 NM,讓 YARN 部分 NM 節點運行在 k8s 上。
然后,資源隔離是混部的核心。雖然 k8s 提供資源管理,但是僅限于 CPU、內存兩個維度,而網絡和磁盤 IO 卻暫未納入考慮[12]。這對于在混部大數據業務而言顯然是不夠的,因為大數據業務可以很輕松地將機器的網絡或磁盤打滿,嚴重影響在線業務。要達到生產的資源隔離,通常需要 Linux 內核級別的支持,這超出本文的范圍和筆者的知識儲備,不再詳述。
最后,資源調度是服務質量的保證。調度器需要考慮物理節點的資源異構、同類業務充分打散分布和業務的部署偏好來優化調度,優化效率并最大程度避免相互干擾。此外,集群調度器會按照優先級來進行資源超發。在業務低峰期,空閑的資源可以用于跑優先級低、延遲不敏感的離線作業,然而在業務出現突發流量或發現在線作業受到離線作業干擾時,集群調度器需要快速讓離線作業退出并讓出資源。
4.HTAP
HTAP 全稱是 Hybrid Transactional Analytical Processing (混合事務分析處理),即同時支持在線事務查詢和分析查詢。前文所說的計算和存儲的流批一體是實時和離線技術棧上的融合,在離線混部是大數據業務與在線業務運維管理上的融合,而 HTAP 就是最終的大數據和在線業務技術棧上的融合。自 2014 年 Gartner 提出該概念后,HTAP 成為了數據庫領域最為熱門的方向。除了簡化 OLTP 和 OLAP 兩套技術棧的復雜架構外,HTAP 還有一個重要的需求背景: 隨著數據場景從企業內部決策支持,到用作為線上增值服務的算法模型輸入(比如推薦、廣告),再到直接作為面向用戶的數據服務(比如淘寶生意參謀、滴滴行車軌跡等),OLTP 和 OLAP 的邊界正變得越來越模糊。
HTAP 從架構來看分為兩類: 單系統同時服務于 OLTP 和 OLAP,或有兩套系統分別服務于 OLTP 和 OLAP。現在業界比較熱門的 TiDB、OceanBase 和 Google 的 F1 Lightning 都屬于后者。在這類系統中,OLTP 和 OLAP 分別有獨立的存儲和計算引擎,并依靠內建的同步機制來將 OLTP 系統中的行存數據同步到 OLAP 系統轉為適合分析業務的列存數據。在此之上,查詢優化器對外提供統一的查詢入口,將不同類型的查詢分別路由到合適的系統中。
比起傳統的基于 Hadoop 生態的數據倉庫,HTAP 的優點是:
內置可靠的數據同步機制,避免建立 OLTP 庫到數據倉庫的復雜 ETL 管道,同時也提高了數據一致性(比如 TiDB 和 F1 Lightning 都提供與 OLTP 一致的可重復讀一致性)。
對用戶友好的統一查詢接口,屏蔽了底層引擎的復雜性,大大降低了 OLAP 的門檻。這使得在有授權的情況下,線上業務團隊能利用 OLAP 進行輕量級數據分析,而數據分析團隊也能利用 OLTP 進行快速的點查。
數據安全性更有保障。將數據在不同組件間移動容易造成權限不一致和安全漏洞,而 HTAP 可以復用 OLTP 的數據權限和避免數據跨組件訪問來避免這些問題。
雖然 HTAP 的愿景非常美好,但要構建經得起業務檢驗的 HTAP 系統并不容易。數據庫和大數據領域先后有多次嘗試,不過目前算得上成功的案例屈指可數,其主要難點在于:
OLTP 和 OLAP 資源的隔離。由于 OLAP 常包含一些資源密集的復雜查詢,OLTP 和 OLAP 公用的組件很容易產生資源競爭,從而干擾優先級更高的 OLTP 查詢。在早些年的案例中,共享計算和存儲的 HTAP 都不能獲得很好的效果,因此最近的 HTAP 數據庫都在硬件級別進行兩者負載的隔離,也就是獨立的存儲和計算。
數據同步機制如何確保數據一致性和新鮮度(freshness)。不同于基于 Hadoop 的數據倉庫通常允許小時級別的數據延遲和不一致窗口,HTAP 通常承諾強一致性以保證一個查詢無論被路由到 OLTP 系統還是 OLAP 系統都能獲得一致結果,這對數據同步機制的性能和容錯性都提出很高的要求。目前在 HTAP 領域稱得上 State of the art 的兩個數據庫里,F1 Lightning 使用無入侵的 CDC 方式進行同步,TiDB 基于 Raft 算法進行數據復制。前者松耦合,但實現比較復雜;后者更加簡潔優雅,但會受 OLTP 設計的約束,比如復制的數據塊大小需要與 OLTP 一致[16]。
淺談大數據的過去、現在和未來
如何利有機結合 OLTP 和 OLAP 工作負載。目前的 HTAP 像同一個門面后的兩套獨立系統,一個查詢要么交給 OLTP 處理,要么交給 OLAP 處理,并沒有產生 1 + 1 > 2 的化學反應。IBM 指出,真正的 OLAP 是在同一個事務里高效地處理 OLTP 和 OLAP 兩種工作負載[15]。要做到這點,靠數據同步的 HTAP 架構大概難以做到,需要從分布式事務算法層面來解決。
盡管 HTAP 還未被廣泛應用,但可以預見未來將在很大程度上影響數據倉庫架構。在數據規模不大、分析需求簡單的場景下,HTAP 將成為最為流行的解決方案。
03、未來:回歸本質
“融合” 是大數據當前發展的大勢,這點從歷史的發展規律角度可以窺見其必然性。對于新出現的技術挑戰,在最初的探索期各類解決方案總是層出不窮,其中采用 Greenfield 方式的解決方案可能會將已有的基礎推倒重來,相比原有技術帶來一定的退化(Regression)。退化限制了新技術的應用場景,導致新舊兩種技術的雙軌制,但只要核心功能沒有太大變化,這樣的割裂這往往只是暫時的。
回顧大數據的發展歷史,“大數據” 一詞原本用于描述數據規模、多樣性和處理性能給數據管理帶來的挑戰,而后續被用于描述為處理這類問題而構建的數據系統,即 “大數據系統”。由于這類系統基于與傳統數據不同的基礎構建,并舍棄后者標配的事務特性,導致難以應用到線上業務,通常只用于數據倉庫、機器學習等對數據延遲、數據準確性要求稍微低一點的場景,而這類業務場景又逐漸被稱為 “大數據業務”。
然而,大數據技術本質是數據密集型的分布式系統,而隨著分布式系統的發展和普及,大數據系統在功能特性和業務場景的限制終將被打破,與新出現的以 Spanner 為代表的 NewSQL 分布式數據庫并無明顯界限。屆時,”大數據” 一詞也許會和很多 buzzword 一樣逐漸消失在歷史的長河,回歸到通用的分布式系統的本質。水平擴展、優秀容錯性、高可用的分布式特性將成為各種系統的標配,無論在 OLTP 或者 OLAP 場景。 (部分內容來源網絡,如有侵權請聯系刪除)
立即免費申請產品試用
免費試用
相關文章推薦
-

用數據分析助力企業決策與業務創新
發布時間:2023-09-26瀏覽量:147次
在數字化時代,數據分析已經成為企業成功的關鍵因素之一。作為國內領先的數據分析廠商,億信華辰一直致力于為各類企業提供最優質的數據分析產品和...查看詳情 -

為什么要學習數據分析?數據分析產出是什么?
發布時間:2022-06-28瀏覽量:1082次
「過去」以往在增量時代,每天都有新的領域、新的市場被開發。尤其是在互聯網、電商等領域的紅利期,似乎只要做好單點的突破就能獲得市場。這個蠻...查看詳情 -

數據分析很痛苦?5個對策、8大方法幫到你!
發布時間:2022-06-15瀏覽量:304次
“對數據敏感,能夠通過數據分析與反饋,不斷改進和優化產品”之類的招聘要求屢見不鮮。誠然,數據分析能力已經成為產品經理不可或缺的技能。數據...查看詳情 -

淺談大數據的過去、現在和未來
發布時間:2022-06-14瀏覽量:592次
相信身處于大數據領域的讀者多少都能感受到,大數據技術的應用場景正在發生影響深遠的變化: 隨著實時計算、Kubernetes 的崛起和 HTAP、流批一體...查看詳情 -

數字經濟時代,企業的核心競爭力究竟是什么?
發布時間:2022-06-14瀏覽量:835次
數字經濟時代對于企業而言意味著全新的挑戰和機遇,如何抓住數字經濟的本質,而不是停留在各種零碎的、華麗的詞藻堆砌,構建企業核心競爭力新的理...查看詳情
相關主題

